This is the multi-page printable view of this section. Click here to print.
Documentation
1 - Overview
Foyle is a project aimed at building agents to help software developers deploy and operate software.
Foyle moves software operations out of the shell and into a literate environment. Using Foyle, users
- operate their infrastructure using VSCode Notebooks
- Foyle executes cells containing shell commands by using a simple API to execute them locally or remotely (e.g. in a container)
- get help from AI’s (ChatGPT, Claude, Bard, etc…) which add cells to the notebook
Using VSCode Notebooks makes it easy for Foyle to learn from human feedback and get smarter over time.
What is Foyle?
Foyle is a web application that runs locally. When you run Foyle you can open up a VSCode Notebook in your browser. Using this notebook you can
- Ask Foyle to assist you by adding cells to the notebook that contain markdown or commands to execute
- Execute the commands in the cells
- Ask Foyle to figure out what to do next based on the output of previous commands
Why use Foyle?
- You are tired of copy/pasting commands from ChatGPT/Claude/Bard into your shell
- You want to move operations into a literate environment so you can easily capture the reasoning behind the commands you are executing
- You want to collect data to improve the AI’s you are using to help you operate your infrastructure
Building Better Agents with Better Data
The goal of foyle is to use this literate environment to collect two types of data with the aim of building better agents
- Human feedback on agent suggestions
- Human examples of reasoning traces
Human feedback
We are all asking AI’s (ChatGPT, Claude, Bard, etc…) to write commands to perform operations. These AI’s often make mistakes. This is especially true when the correct answer depends on internal knowledge which the AI doesn’t have.
Consider a simple example, lets ask ChatGPT
What's the gcloud logging command to fetch the logs for the hydros manifest named hydros?
ChatGPT responds with
gcloud logging read "resource.labels.manifest_name='hydros' AND logName='projects/YOUR_PROJECT_ID/logs/hydros'"
This is wrong; ChatGPT even suspects its likely to be wrong because it doesn’t have any knowledge of the logging scheme used by hydros. As users, we would most likely copy the command into our shell and iterate on it until we come up with the correct command; i.e
gcloud logging read 'jsonPayload."ManifestSync.Name"="hydros"'
This feedback is gold. We now have ground truth data (prompt, human corrected answer) that we could use to improve our AIs. Unfortunately, today’s UX (copy and pasting into the shell)
means we are throwing this data away.
The goal of foyle’s literate environment is to create a UX that allows us to easily capture
- The original prompt
- The AI provided answer
- Any corrections the user makes.
Foyle aims to continuously use this data to retrain the AI so that it gets better the more you use it.
Reasoning Traces
Everyone is excited about the ability to build agents that can reason and perform complex tasks e.g. Devin. To build these agents we will need examples of reasoning traces that can be used to train the agent. This need is especially acute when it comes to building agents that can work with our private, internal systems.
Even when we start with the same tools (Kubernetes, GitHub Actions, Docker, Vercel, etc…), we end up adding tooling on top of that. These can be simple scripts to encode things like naming conventions or they may be complex internal developer platforms. Either way, agents need to be trained to understand these platforms if we want them to operate software on our behalf.
Literate environments (e.g. Datadog Notebooks) are great for routine operations and troubleshooting. Using literate environments to operate infrastructure leads to a self documenting process that automatically captures
- Human thinking/analysis
- Commands/operations executed
- Command output
Using literate environments provides a superior experience to copy/pasting commands and outputs into a GitHub issue/slack channel/Google Doc to create a record of what happened.
More importantly, the documents produced by literate environments contain essential information for training agents to operate our infrastructure.
Where should I go next?
- Getting Started: Get started with $project
- FAQ: Frequently asked questions
2 - Getting Started
Installation
Download the latest release from the releases page
On Mac you may need to remove the quarantine attribute from the binary
xattr -d com.apple.quarantine /path/to/foyle
Setup
Download the static assets for foyle
foyle assets download- This downloads the static assets for foyle.
- The assets are stored in
${HOME}/.foyle/assets.
Configure your OpenAPI key
foyle config set openai.apiKeyFile=/path/to/openai/apikey- If you don’t have a key, go to OpenAI to obtain one
Start the server
foyle serveBy default foyle uses port 8080 for the http server and port 9080 for gRPC
If you need to use different ports you can configure this as follows
foyle config set server.httpPort=<YOUR HTTP PORT> foyle config set server.grpcPort=<YOUR GRPC PORT>
Try it out!
Now that foyle is running you can open up VSCode in your web browser and start interacting with foyle.
Open up your browser and go to http://localhost:8080/workbench
The first time you open the workbench you will be prompted to choose a theme as shown below.
- Choose your theme and then click
mark done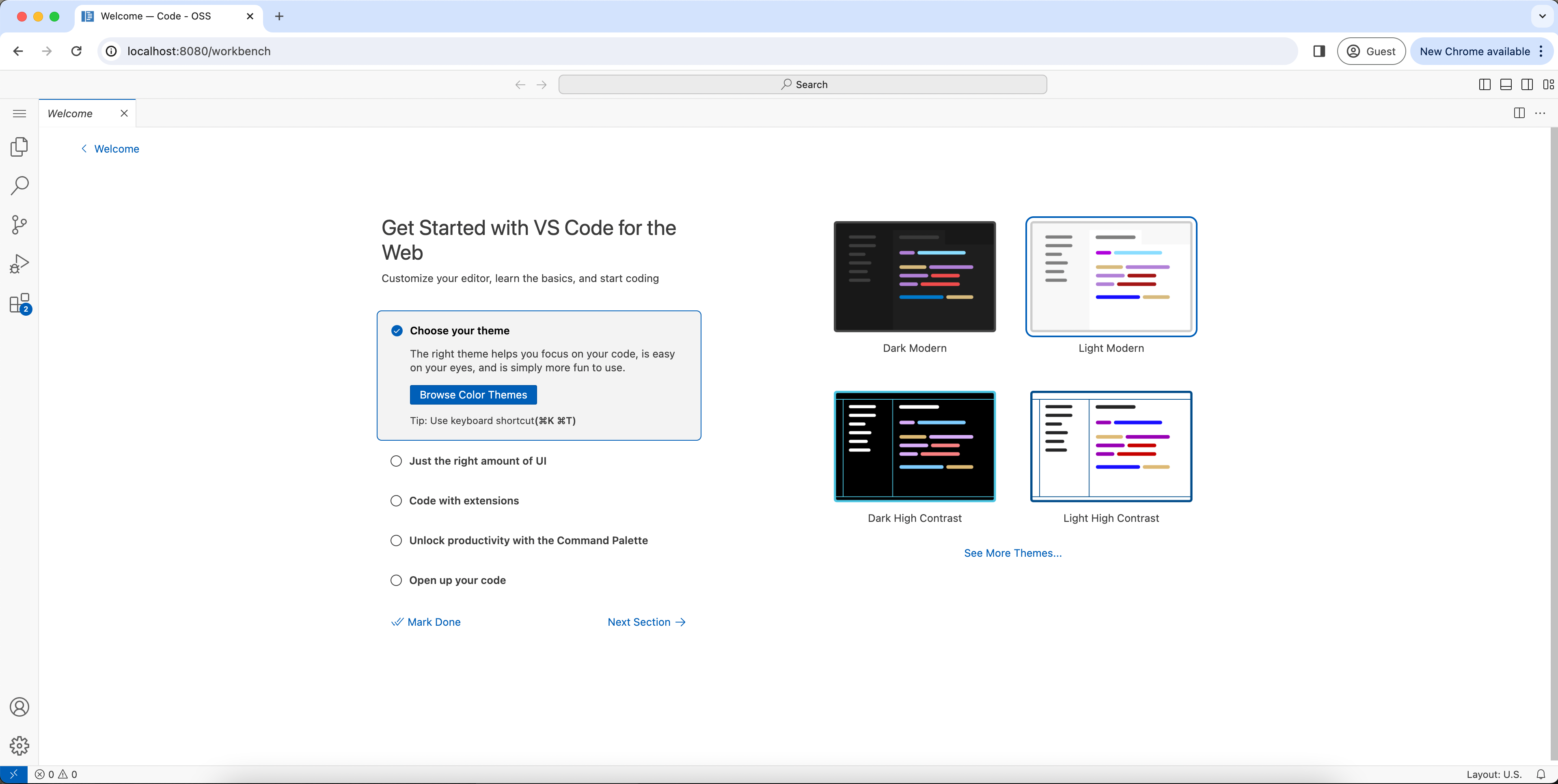
- Choose your theme and then click
Open the explorer tab by clicking the icon in the left hand side navigation bar
Inside the explorer tab click the link to
add a folder- Unfortunately Open Folder doesn’t work reliably. jlewi/foyle#21 is tracking this.
This should open a file explorer and you should select the folder where you want your foyle notebooks to be saved
- Your browser will likely prompt you to allow the site to access the file system; you need to allow this
You should now see the folder you selected in the explorer tab
Start a new notebook by clicking the
+icon in the explorer tabGive your notebook the “.foyle” extension
- Your notebook must have the “.foyle” extension so that vscode knows to open it using foyle
Click on your new notebook to open it inside VSCode’s notebook editor
You can now add code and notebook cells like you normally would in vscode
To ask Foyle for help do one of the following
- Open the command pallet and search for
Foyle generate a completion - Use the shortcut key:
- “win;” - on windows
- “cmd;” - on mac
- Open the command pallet and search for
Customizing Foyle VSCode Extension Settings
Customizing the server endpoints
If you are running the Foyle server on a different port or address then you will need to change Foyle’s VSCode settings.
- Open the settings panel; you can click the gear icon in the lower left window and then select settings
- Search for
Foyle - Set
Foyle-notebook: Agent-addressto the address of the Foyle server to use as the Agent- The Agent handles requests to generate completions
- Set
Foyle-notebook: Executor-addressto the address of the Foyle server to use as the Executor- The Executor handles requests to execute commands
Customizing the keybindings
If you are unhappy with the default key binding to generate a completion you can change it as follows
- Click the gear icon in the lower left window and then select “Keyboard shortcuts”
- Search for “Foyle”
- Change the keybinding for
Foyle: generate a completionto the keybinding you want to use
Where to go next
3 - Markdown Support
Markdown Support
Foyle supports markdown files. Using Foyle you can
- Open existing markdown files in the VSCode Notebook Editor
- Automatically render and execute code blocks as code cells in your notebook
- Save your notebook as a markdown file
To use markdown files in Foyle just give your file an extension of .md or .markdown. When you open the file in Foyle
it will be automatically rendered as a notebook.
Important When persisting notebooks as markdown cell outputs are currently not saved. This feature may be added in the future.
When to use Markdown Files
Markdown files are useful when you are working in a shared code repository that is already using markdown files for documentation and playbooks.
4 - Azure OpenAI
What You’ll Learn
How to configure Foyle to use Azure OpenAI
Prerequisites
- You need an Azure Account (Subscription)
- You need access to Azure Open AI
Setup Azure OpenAI
You need the following Azure OpenAI resources:
Azure Resource Group - This will be an Azure resource group that contains your Azure OpenAI resources
Azure OpenAI Resource Group - This will contain your Azure OpenAI model deployments
You can use the Azure CLI to check if you have the required resources
az cognitiveservices account list --output=table Kind Location Name ResourceGroup ------ ---------- -------------- ---------------- OpenAI eastus ResourceName ResourceGroupNote You can use the pricing page to see which models are available in a given region. Not all models are available an all regions so you need to select a region with the models you want to use with Foyle.
Foyle currently uses gpt-3.5-turbo-0125
A GPT3.5 deployment
Use the CLI to list your current deployments
az cognitiveservices account deployment list -g ${RESOURCEGROUP} -n ${RESOURCENAME} --output=tableIf you need to create a deployment follow the instructions
Setup Foyle To Use Azure Open AI
Set the Azure Open AI BaseURL
We need to configure Foyle to use the appropriate Azure OpenAI endpoint. You can use the CLI to determine the endpoint associated with your resource group
az cognitiveservices account show \
--name <myResourceName> \
--resource-group <myResourceGroupName> \
| jq -r .properties.endpoint
Update the baseURL in your Foyle configuration
foyle config set azureOpenAI.baseURL=https://endpoint-for-Azure-OpenAI
Set the Azure Open AI API Key
Use the CLI to obtain the API key for your Azure OpenAI resource and save it to a file
az cognitiveservices account keys list \
--name <myResourceName> \
--resource-group <myResourceGroupName> \
| jq -r .key1 > ${HOME}/secrets/azureopenai.key
Next, configure Foyle to use this API key
foyle config set azureOpenAI.apiKeyFile=/path/to/your/key/file
Specify model deployments
You need to configure Foyle to use the appropriate Azure deployments for the models Foyle uses.
Start by using the Azure CLI to list your deployments
az cognitiveservices account deployment list --name=${RESOURCE_NAME} --resource-group=${RESOURCE_GROUP} --output=table
Configure Foyle to use the appropriate deployments
foyle config set azureOpenAI.deployments=gpt-3.5-turbo-0125=<YOUR-GPT3.5-DEPLOYMENT-NAME>
Troubleshooting:
Rate Limits
If Foyle is returning rate limiting errors from Azure OpenAI, use the CLI to check the rate limits for your deployments
az cognitiveservices account deployment list -g ${RESOURCEGROUP} -n ${RESOURCENAME}
Azure OpenAI sets the default values to be quite low; 1K tokens per minute. This is usually much lower than your allotted quota. If you have available quota, you can use the UI or to increase these limits.
5 - Ollama
What You’ll Learn
How to configure Foyle to use models served by Ollama
Prerequisites
- Follow [Ollama’s docs] to download Ollama and serve a model like
llama2
Setup Foyle to use Ollama
Foyle relies on Ollama’s OpenAI Chat Compatability API to interact with models served by Ollama.
Configure Foyle to use the appropriate Ollama baseURL
foyle config set openai.baseURL=http://localhost:11434/v1- Change the server and port to match how you are serving Ollama
- You may also need to change the scheme to https; e.g. if you are using a VPN like Tailscale
Configure Foyle to use the appropriate Ollama model
foyle config agent.model=llama2- Change the model to match the model you are serving with Ollama
You can leave the
apiKeyFileunset since you aren’t using an API key with OllamaThat’s it! You should now be able to use Foyle with Ollama
6 - Observability
What You’ll Learn
How to use OpenTelemetry to monitor Foyle.
Configure Honeycomb
To configure Foyle to use Honeycomb as a backend you just need to set the telemetry.honeycomb.apiKeyFile
configuration option to the path of a file containing your Honeycomb API key.
foyle config set telemetry.honeycomb.apiKeyFile = /path/to/apikey
7 - Reference
This is a placeholder page that shows you how to use this template site.
If your project has an API, configuration, or other reference - anything that users need to look up that’s at an even lower level than a single task - put (or link to it) here. You can serve and link to generated reference docs created using Doxygen,
Javadoc, or other doc generation tools by putting them in your static/ directory. Find out more in Adding static content. For OpenAPI reference, Docsy also provides a Swagger UI layout and shortcode that renders Swagger UI using any OpenAPI YAML or JSON file as source.
7.1 - FAQ
Why not use the Jupyter Kernel?
The Jupyter kernel creates a dependency on the python tool chain. If you aren’t already using Python this can be a hassle. Requiring a python environment is an unnecessary dependency if all we want to do is create a simple server to execute shell commands.
If users want to execute python code they can still do it by invoking python in the cell.
What are some related projects?
- cleric.io Company building a fully autonomous SRE teammate.
- runme.dev Devops workflows built with markdown.
- k8sgpt.ai Tool to scan your K8s clusters and explain issues and potential fixes.
- Honeycomb Query Assitant
- Fiberplane Offer collaborative notebooks for incidement management and post-mortems
- Kubecost Offers a Jupyter notebook interface for analyzing Kubernetes cost data.
- k9s Offers a terminal based UI for interacting with Kubernetes.
- Waveterm AI Open Source Terminal
- warp.dev AI based terminal which now supports notebooks
8 - Contribution Guidelines
We use Hugo to format and generate our website, the Docsy theme for styling and site structure, and Netlify to manage the deployment of the site. Hugo is an open-source static site generator that provides us with templates, content organisation in a standard directory structure, and a website generation engine. You write the pages in Markdown (or HTML if you want), and Hugo wraps them up into a website.
All submissions, including submissions by project members, require review. We use GitHub pull requests for this purpose. Consult GitHub Help for more information on using pull requests.
Quick start with Netlify
Here’s a quick guide to updating the docs. It assumes you’re familiar with the GitHub workflow and you’re happy to use the automated preview of your doc updates:
- Fork the Foyle repo on GitHub.
- Make your changes and send a pull request (PR).
- If you’re not yet ready for a review, add “WIP” to the PR name to indicate it’s a work in progress. (Don’t add the Hugo property “draft = true” to the page front matter, because that prevents the auto-deployment of the content preview described in the next point.)
- Wait for the automated PR workflow to do some checks. When it’s ready, you should see a comment like this: deploy/netlify — Deploy preview ready!
- Click Details to the right of “Deploy preview ready” to see a preview of your updates.
- Continue updating your doc and pushing your changes until you’re happy with the content.
- When you’re ready for a review, add a comment to the PR, and remove any “WIP” markers.
Updating a single page
If you’ve just spotted something you’d like to change while using the docs, we have a shortcut for you:
- Click Edit this page in the top right hand corner of the page.
- If you don’t already have an up to date fork of the project repo, you are prompted to get one - click Fork this repository and propose changes or Update your Fork to get an up to date version of the project to edit. The appropriate page in your fork is displayed in edit mode.
- Follow the rest of the Quick start with Netlify process above to make, preview, and propose your changes.
Previewing your changes locally
If you want to run your own local Hugo server to preview your changes as you work:
Follow the instructions in Getting started to install Hugo and any other tools you need. You’ll need at least Hugo version 0.45 (we recommend using the most recent available version), and it must be the extended version, which supports SCSS.
Fork the Foyle repo repo into your own project, then create a local copy using
git clone. Don’t forget to use--recurse-submodulesor you won’t pull down some of the code you need to generate a working site.git clone --recurse-submodules --depth 1 https://github.com/jlewi/foyle.gitRun
hugo serverin the site root directory. By default your site will be available at http://localhost:1313/. Now that you’re serving your site locally, Hugo will watch for changes to the content and automatically refresh your site.Continue with the usual GitHub workflow to edit files, commit them, push the changes up to your fork, and create a pull request.
Creating an issue
If you’ve found a problem in the docs, but you’re not sure how to fix it yourself, please create an issue in the Foyle repo. You can also create an issue about a specific page by clicking the Create Issue button in the top right hand corner of the page.
Useful resources
- Docsy user guide: All about Docsy, including how it manages navigation, look and feel, and multi-language support.
- Hugo documentation: Comprehensive reference for Hugo.
- Github Hello World!: A basic introduction to GitHub concepts and workflow.
9 - Blog
Blogs related to Foyle.
Logging Implicit Human Feedback
Foyle is an open source assistant to help software developers deal with the pain of devops. Developers are expected to operate their software which means dealing with the complexity of Cloud. Foyle aims to simplify operations with AI. One of Foyle’s central premises is that creating a UX that implicitly captures human feedback is critical to building AIs that effectively assist us with operations. This post describes how Foyle logs that feedback.
The Problem
As software developers, we all ask AIs (ChatGPT, Claude, Bard, Ollama, etc.…) to write commands to perform operations. These AIs often make mistakes. This is especially true when the correct answer depends on internal knowledge, which the AI doesn’t have.
- What region, cluster, or namespace is used for dev vs. prod?
- What resources is the internal code name “caribou” referring to?
- What logging schema is used by our internal CICD tool?
The experience today is
- Ask an assistant for one or more commands
- Copy those commands to a terminal
- Iterate on those commands until they are correct
When it comes to building better AIs, the human feedback provided by the last step is gold. Yet today’s UX doesn’t allow us to capture this feedback easily. At best, this feedback is often collected out of band as part of a data curation step. This is problematic for two reasons. First, it’s more expensive because it requires paying for labels (in time or money). Second, if we’re dealing with complex, bespoke internal systems, it can be hard to find people with the requisite expertise.
Frontend
If we want to collect human feedback, we need to create a single unified experience for
- Asking the AI for help
- Editing/Executing AI suggested operations
If users are copying and pasting between two different applications the likelihood of being able to instrument it to collect feedback goes way down. Fortunately, we already have a well-adopted and familiar pattern for combining exposition, commands/code, and rich output. Its notebooks.
Foyle’s frontend is VSCode notebooks. In Foyle, when you ask an AI for assistance, the output is rendered as cells in the notebook. The cells contain shell commands that can then be used to execute those commands either locally or remotely using the notebook controller API, which talks to a Foyle server. Here’s a short video illustrating the key interactions.
Crucially, cells are central to how Foyle creates a UX that automatically collects human feedback. When the AI generates a cell, it attaches a UUID to that cell. That UUID links the cell to a trace that captures all the processing the AI did to generate it (e.g any LLM calls, RAG calls, etc…). In VSCode, we can use cell metadata to track the UUID associated with a cell.
When a user executes a cell, the frontend sends the contents of the cell along with its UUID to the Foyle server. The UUID then links the cell to a trace of its execution. The cell’s UUID can be used to join the trace of how the AI generated the cell with a trace of what the user actually executed. By comparing the two we can easily see if the user made any corrections to what the AI suggested.

Traces
Capturing traces of the AI and execution are essential to logging human feedback. Foyle is designed to run on your infrastructure (whether locally or in your Cloud). Therefore, it’s critical that Foyle not be too opinionated about how traces are logged. Fortunately, this is a well-solved problem. The standard pattern is:
- Instrument the app using structured logs
- App emits logs to stdout and stderr
- When deploying the app collect stdout and stderr and ship them to whatever backend you want to use (e.g. Google Cloud Logging, Datadog, Splunk etc…)
When running locally, setting up an agent to collect logs can be annoying, so Foyle has the built-in ability to log to files. We are currently evaluating the need to add direct support for other backends like Cloud Logging. This should only matter when running locally because if you’re deploying on Cloud chances are your infrastructure is already instrumented to collect stdout and stderr and ship them to your backend of choice.
Don’t reinvent logging
Using existing logging libraries that support structured logging seems so obvious to me that it hardly seems worth mentioning. Except, within the AI Engineering/LLMOps community, it’s not clear to me that people are reusing existing libraries and patterns. Notably, I’m seeing a new class of observability solutions that require you to instrument your code with their SDK. I think this is undesirable as it violates the separation of concerns between how an application is instrumented and how that telemetry is stored, processed, and rendered. My current opinion is that Agent/LLM observability can often be achieved by reusing existing logging patterns. So, in defense of that view, here’s the solution I’ve opted for.
Structured logging means that each log line is a JSON record which can contain arbitrary fields. To Capture LLM or RAG requests and responses, I log them; e.g.
request := openai.ChatCompletionRequest{
Model: a.config.GetModel(),
Messages: messages,
MaxTokens: 2000,
Temperature: temperature,
}
log.Info("OpenAI:CreateChatCompletion", "request", request)
This ends up logging the request in JSON format. Here’s an example
{
"severity": "info",
"time": 1713818994.8880482,
"caller": "agent/agent.go:132",
"function": "github.com/jlewi/foyle/app/pkg/agent.(*Agent).completeWithRetries",
"message": "OpenAI:CreateChatCompletion response",
"traceId": "36eb348d00d373e40552600565fccd03",
"resp": {
"id": "chatcmpl-9GutlxUSClFaksqjtOg0StpGe9mqu",
"object": "chat.completion",
"created": 1713818993,
"model": "gpt-3.5-turbo-0125",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "To list all the images in Artifact Registry using `gcloud`, you can use the following command:\n\n```bash\ngcloud artifacts repositories list --location=LOCATION\n```\n\nReplace `LOCATION` with the location of your Artifact Registry. For example, if your Artifact Registry is in the `us-central1` location, you would run:\n\n```bash\ngcloud artifacts repositories list --location=us-central1\n```"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 329,
"completion_tokens": 84,
"total_tokens": 413
},
"system_fingerprint": "fp_c2295e73ad"
}
}
A single request can generate multiple log entries. To group all the log entries related to a particular request, I attach a trace id to each log message.
func (a *Agent) Generate(ctx context.Context, req *v1alpha1.GenerateRequest) (*v1alpha1.GenerateResponse, error) {
span := trace.SpanFromContext(ctx)
log := logs.FromContext(ctx)
log = log.WithValues("traceId", span.SpanContext().TraceID())
Since I’ve instrumented Foyle with open telemetry(OTEL), each request is automatically assigned a trace id. I attach that trace id to all the log entries associated with that request. Using the trace id assigned by OTEL means I can link the logs with the open telemetry trace data.
OTEL is an open standard for distributed tracing. I find OTEL great for instrumenting my code to understand how long different parts of my code took, how often errors occur and how many requests I’m getting. You can use OTEL for LLM Observability; here’s an example. However, I chose logs because as noted in the next section they are easier to mine.
Aside: Structured Logging In Python
Python’s logging module supports structured logging. In Python you can use the extra argument to pass an arbitrary dictionary of values. In python the equivalent would be:
logger.info("OpenAI:CreateChatCompletion", extra={'request': request, "traceId": traceId})
You then configure the logging module to use the python-json-logger formatter to emit logs as JSON. Here’s the logging.conf I use for Python.
Logs Need To Be Mined
Post-processing your logs is often critical to unlocking the most valuable insights. In the context of Foyle, I want a record for each cell that captures how it was generated and any subsequent executions of that cell. To produce this, I need to write a simple ETL pipeline that does the following:
- Build a trace by grouping log entries by trace ID
- Reykey each trace by the cell id the trace is associated with
- Group traces by cell id
This logic is highly specific to Foyle. No observability tool will support it out of box.
Consequently, a key consideration for my observability backend is how easily it can be wired up to my preferred ETL tool. Logs processing is such a common use case that most existing logging providers likely have good support for exporting your logs. With Google Cloud Logging for example it’s easy to setup log sinks to route logs to GCS, BigQuery or PubSub for additional processing.
Visualization
The final piece is being able to easily visualize the traces to inspect what’s going on. Arguably, this is where you might expect LLM/AI focused tools might shine. Unfortunately, as the previous section illustrates, the primary way I want to view Foyle’s data is to look at the processing associated with a particular cell. This requires post-processing the raw logs. As a result, out of box visualizations won’t let me view the data in the most meaningful way.
To solve the visualization problem, I’ve built a lightweight progressive web app(PWA) in Go (code) using maxence-charriere/go-app. While I won’t be winning any design awards, it allows me to get the job done quickly and reuse existing libraries. For example, to render markdown as HTML I could reuse the Go libraries I was already using (yuin/goldmark). More importantly, I don’t have to wrestle with a stack(typescript, REACT, etc…) that I’m not proficient in. With Google Logs Analytics, I can query the logs using SQL. This makes it very easy to join and process a trace in the web app. This makes it possible to view traces in real-time without having to build and deploy a streaming pipeline.
Where to find Foyle
Please consider following the getting started guide to try out an early version of Foyle and share your thoughts by email(jeremy@lewi.us) on GitHub(jlewi/foyle) or on twitter (@jeremylewi)!
About Me
I’m a Machine Learning platform engineer with over 15 years of experience. I create platforms that facilitate the rapid deployment of AI into production. I worked on Google’s Vertex AI where I created Kubeflow, one of the most popular OSS frameworks for ML.
I’m open to new consulting work and other forms of advisory. If you need help with your project, send me a brief email at jeremy@lewi.us.